
Facebook Reality Labs, the research division of the company, headed work on creating a fairly realistic avatars of virtual reality. The new study group aims to support new faces.
Most avatars currently used in virtual reality, rather a cartoon than a human, basically it is a way to avoid this when a more “realistic” avatars are becoming more visually repulsive as you get closer, but not enough to understand how a person really looks and moves.
Predecessor: avatars codecs
The project “Codec Avatar” in Facebook Reality Labs aims to overcome the effect of “sinister valley” using a combination of machine learning and computer vision to create Hyper realistic representations of users. Teaching the system to understand how a person’s face, and then instructing her to recreate this image based on the data from the cameras inside the gear VR headset, the project has demonstrated truly impressive results .
The reconstruction of the typical expressions with sufficient accuracy to be convincing, is already a problem, but there are many extreme cases with which to deal, either of which can throw the entire system and plunge the avatar back to the “uncanny valley”.
According to researchers with Facebook, the big problem is that “it is impractical to have a uniform sample of all possible [facial] expressions” because there are just so many different ways to distort the face. Ultimately, this means that in these examples, the system has a gap, and this leads to confusion when she sees something new.
Successor: the modular avatars codecs
Researchers hang Choo, Shugao MA, Fernando De La Torre, Sanya Fidler and Yaser Sheikh offer a solution in a recently published research article titled “Expressive modular telepresence via avatars codecs” .
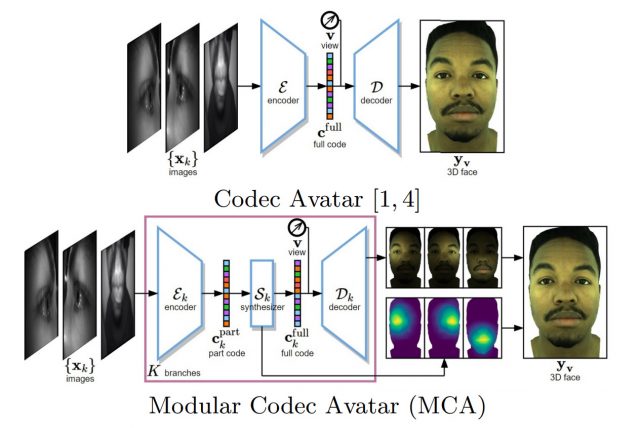
While the original system of avatars codec attempts to match all the expression from your dataset with the input data it sees, the system is modular avatars codecs divides the task of individual facial features such as the eyes and mouth, allowing her to synthesize the most accurate position through the merger of best fit from several different poses in her data.
Codec Avatars in Modular modular encoder first extracts information from each individual camera mounted on the headset. Followed by modular synth, which estimates complete facial expression along with his weight mixing ratios based on the information extracted in the same modular branch. Finally, several benchmark 3D entities are combined from different modules and are mixed together to form the final result of the expression.
The aim is to improve the range of expressions that can be accurately represented without the need to enter the additional data for training. We can say that the system is Modular Codec Avatar developed in order to improve insights on how should look a person in comparison with the original system Codec Avatar, which relied more on a direct comparison.
The task is to portray a silly face
One of the main advantages of this approach is to improve the system’s ability to recreate a new facial expression that she was not initially trained, for example, when people intentionally distort their faces in funny ways, especially because people usually don’t make such faces. The researchers called this specific the advantage in his article, stating that “funny facial expressions are part of social interaction. Model Modular Codec Avatar, of course, can better facilitate this task, due to the larger expression.”
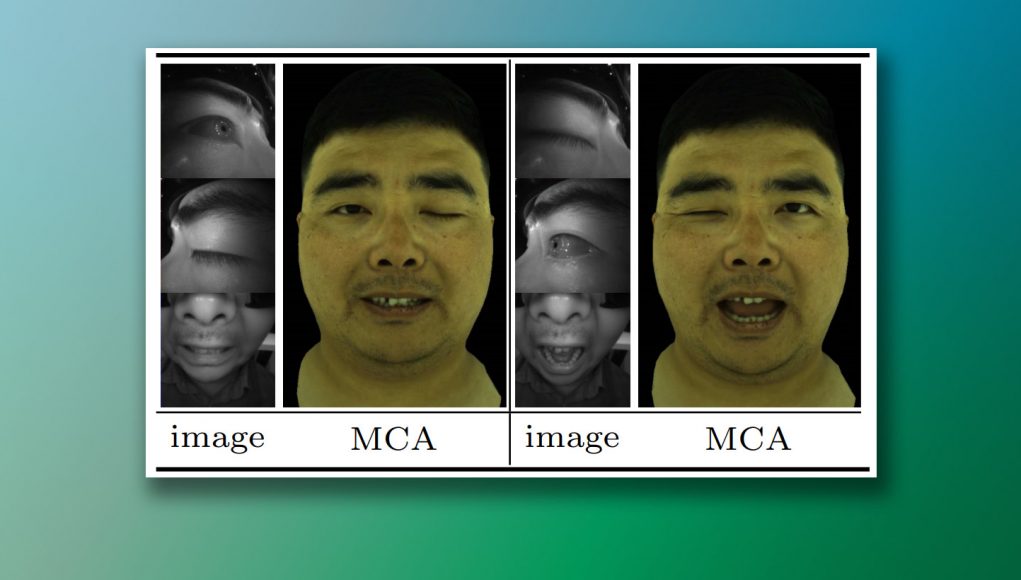
They tested it by making “artificial” funny faces by random shuffling of facial features from completely different positions (example: the left eye of the {posture A}, the right eye of the {posture B} of mouth and {posture C}) and look whether the system will give realistic results, given the unexpectedly dissimilar input data.
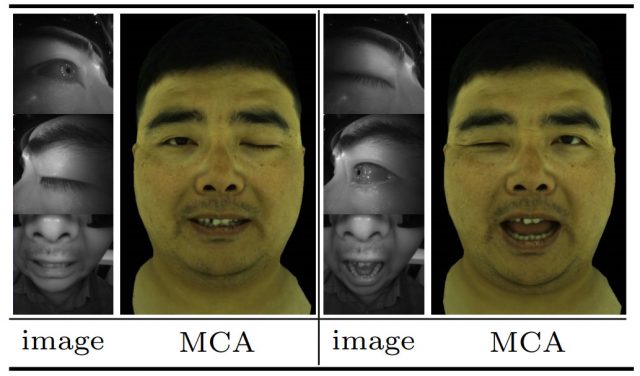
“You can see [the figure above] that avatars modular codecs create a natural, flexible expression, although such expressions are never met completely in the training set,” say the researchers.
Increase eye
The researchers found that the system is Modular Codec Avatar not only makes funny faces, but also improves the realism of the face, eliminating the difference in position of eyes, inherent in wearing the headset.
In practical virtual telepresence, we can see that users often don’t open my eyes fully in a natural way. This may be due to the pressure of the muscles from wearing a headset and displaying light sources near the eyes. To solve this problem we introduce the control knob to strengthen the eyes.
This allows the system to subtly change the eyes so they were closer to how they would look in fact, if the user was not wearing the headset.

Although the idea of recreating individuals by combining elements from disparate fragments of these examples is in itself not new, the researchers say that “instead of using linear or shallow objects on the 3D mesh [as with previous methods], our modules occur in concealed spaces, learning deep neural networks. This allows you to capture complex nonlinear effects and to create facial animation at a new level of realism.”
This approach is also an attempt to make this representation more practical avatar. Training data required to achieve good results using the Codec Avatars, first requires capturing a real user’s face in many complex facial expressions. Avatars of the modular codec achieve similar results with greater expressiveness with fewer training data.
It will be some time before anyone with no access to light the scene for a facial scan can be so accurately represented in virtual reality, but with the constant progress it seems plausible that one day users will be able to quickly and easily remove their own model of a face using a smartphone app, and then load it as the basis for avatar.
Source







