
Batch processing in cloud-native environments Volcano: Group scheduling of containers in Kuberntes
19.10.2021Author /
Editor:
Thomas Joos
Ulrike Ostler
Volcano is a project of the Cloud Native Computing Foundation (CNCF). It is mainly used as a batch system in AI and big data applications when the environment is based on Kubernetes.
Companies on the topic
 The CNCF project for batch processing has been called “Volcano” since 2019.
The CNCF project for batch processing has been called “Volcano” since 2019.
(Photo by Reimund Bertrams on Pixabay)
The CNCF project Volcano is a batch system built on top of Kubernetes. Workloads primarily focus on workloads from the field of AI (machine learning and deep learning) and other big data applications that cause a high computing load and must be optimally planned in the Kubernetes cluster.
Frameworks like Tensorflow, Spark, Pytorch, MPI, Flink, Argo, Mindspore, and PaddlePaddle that require high workload workloads work well with Volcano. Volcano supports integration with various computing frameworks, such as Kubeflow and Kubegene.
Volcano adds various features to Kubernetes. These include scheduling extensions, job management extensions and accelerators such as GPU and FPGA (Field Programmable Gate Array).
Grouped scheduling for containers
Volcano is one of the projects that emerged from “Kube Batch”. The project was originally created to better group containers and better plan resources.
Especially for AI and big data solutions, Volcano in Kubernetes clusters is an important component for better resource utilization. Volcano makes it possible to significantly accelerate AI workloads in Kubernetes clusters.
Originally accepted by the CNCF in 2015 as a sandbox project ‘Kubernetes-native system for high-performance workloads’, it was named Volcano in 2019. The source code and issues of the project can also be found in the Volcano branch on Github.
Add-on for the Kubernetes scheduler
The scheduler in Kubernetes schedules containers individually. This makes sense for many scenarios, but rarely for workloads with compute-intensive tasks. Especially in the training of AI environments and also in big data analyses, entire groups of containers often play an important role.
If an application requires multiple containers to run, it can happen with the default scheduler in Kubernetes, caused by the individual scheduling, that individual containers of the group cannot start because there are not enough resources. As a result, such workloads either run less effectively, or not at all.
At the same time, the already started containers of the group cause resources that bring nothing at all, because an essential part of the group is missing. This is Volcano’s approach. The solution combines the entire group of interdependent containers and plans their resources together.
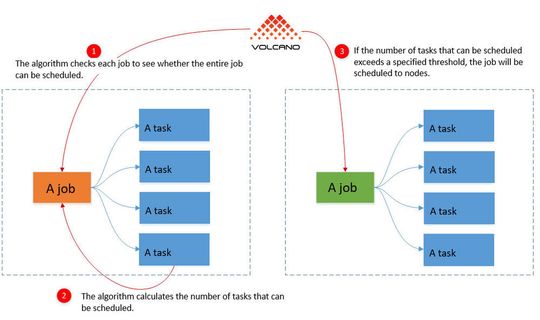 “Volcano” helps in the optimal provision of resource-hungry workloads in the AI field.
“Volcano” helps in the optimal provision of resource-hungry workloads in the AI field.
(Picture: CNCF.io)
If you cannot start all containers in the group, Volcano prevents all containers in the group from starting. This significantly relieves the Kubernetes cluster, since in this case at least resources are available for other container and container groups. If there are several such groups running in a cluster, then the use of Volcano makes perfect sense.
Automatic resource allocation for containers
Through its internal functions, Volcano has a complete overview of the individual containers on Kubernetes, but also of groups of containers that are jointly available for a workload. In addition to grouping and sharing container resources, the software can also identify which nodes are best suited to deploy each container in a group.
The CPU, memory, GPU and other resources can also be specifically scheduled and made available to the containers of a group. Volcano knows the free resources and the maximum utilization of all nodes. Based on this information, Volcano selects the most appropriate node for each container.
Volcano also offers the opportunity to work with priorities. Functions such as Domain Resource Fairness (DRF) and Binpack are also integrated into Volcano and can be taken into account in resource planning. If several groups compete with each other or are not to be used together on one node, this can be taken into account with Volcano.
How Volcano works
Domain Resource Fairness (DRF) can prioritize jobs, including in YARN and Mesos. For example, DRF can also prioritize jobs that require fewer resources. The result is that the cluster can run more jobs and small tasks are not blocked by large applications. As an order, DRF in Volcano defines the totality of all necessary containers for a defined task.
The Binpack algorithm tries to maximize the utilization of all nodes in the cluster. Configurations can be made via which nodes are completely occupied before Volcano occupies further nodes. Binpack schedules the utilization of all nodes in the cluster and then schedules the individual jobs according to these conditions.
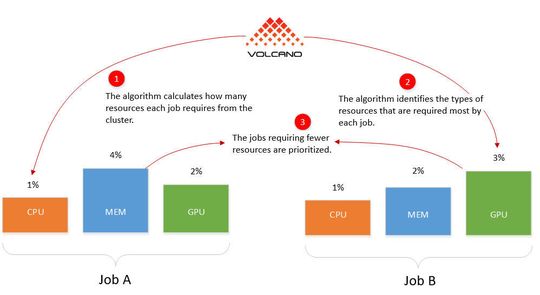 “Volcano” works with various algorithms for resource optimization in the Kubernetes cluster.
“Volcano” works with various algorithms for resource optimization in the Kubernetes cluster.
(Picture: CNCF.io)
The queuing algorithm can control the entire resource allocation of a cluster. This technique is also used in YARN. If multiple container groups share a pool of resources in a cluster, Volcano can control which group needs more resources.
As a result, Volcano recognizes which group is likely to use fewer resources in such a scenario and can execute this group first. Once their tasks are completed, Volcano can schedule the group with the higher resource utilization. Volcano can weight its various scheduling algorithm plugins differently.
Ergo: If a Kubernetes cluster uses workloads that are built on multiple containers and pods and consume a lot of resources, Volcano can bring significant benefits. The use is particularly worthwhile when working with AI workloads, for example for machine learning and deep learning. But other, resource-hungry workloads in the big data area of rendering and comprehensive calculations also benefit from Volcano.
Finally, Volcano also brings some advantages to the other workloads in the cluster, as the much better resource planning also allows the other workloads to use more resources, or are preferred at startup because they need fewer resources and are therefore faster with their work.
Article files and article links
(ID:47697999)








